November 8, 2023
Machine learning: a breakthrough in transportation technology? A computer takeover that can’t be trusted? The answer to these questions will depend on who you ask—and for us, it also depends on what we’re talking about when we say machine learning.
There’s the on-paper definition. Machine learning is a subset of artificial intelligence that involves the use of data to improve a system’s performance. Through machine learning, we can build algorithms and statistical models that make predictions based on data, and learn and improve on prior experiences.
But this definition is missing something that’s critical to machine learning’s success: the partnership of machines and humans. Machine learning can take us to new heights, enabling us to solve complex problems more efficiently and accurately to make transportation systems safer and smarter. But these outcomes are only possible when machine learning algorithms are paired with human guidance and judgment.
At Kittelson, we’ve experienced firsthand the benefits of applying machine learning to solve transportation challenges. Given the speed at which machine learning applications are evolving in our profession, earlier this year, we decided to launch an internal artificial intelligence and machine learning (AI/ML) task force to more formally explore the opportunities, and map out a process for developing, testing, applying, and verifying machine learning processes to improve the way we work.
We’re excited about the role machine learning can play to support the work we do as engineers and planners. Think of it like a highly intelligent team member who is new to the industry and needs training and guidance. How can we guide this team member to learn transportation and apply their exciting skillsets on our projects?
As we’ve explored this question, we’ve developed a framework that demystifies the process of integrating machine learning into our work, and demonstrates how human decision-makers can stay in the driver’s seat. Read on to learn all about it!

Think of machine learning like a highly intelligent team member who is new to the industry and needs training and guidance. How can we guide this team member to learn transportation and apply their exciting skillsets on our projects?
Opportunities & Challenges of Machine Learning in Transportation
Machine learning holds many exciting opportunities for transportation engineering and planning. In our work, we can leverage machine learning to process data, debug models, uncover hidden trends, and explore new project opportunities, among other benefits. Some of the biggest opportunities for transportation engineering include:
- Improvements in real-time applications: Machine learning models offer an efficient way to apply large volumes of real-time data to real-time decision-making, which can aid in traffic management, signal timing, crash predictions, and more.
- Data analysis, processing, and utilization: AI and machine learning can assist in analyzing and processing large volumes of data, particularly when traditional statistical models cannot effectively handle complex relationships between parameters. The use of AI also allows for more efficient utilization of data, which can lead to improved decision-making and more effective transportation planning.
- Hidden trend identification: These technologies can help identify hidden trends and patterns in data, which may not be apparent through simple models.
- Model debugging: AI can aid in debugging machine learning models, making it easier to identify and address errors or issues in the models’ codes or functionalities.
- Complex relationship exploration: AI techniques are valuable when dealing with complex relationships and dimensions in data, enabling a better understanding of intricate patterns within the data.
However, it’s important to recognize that the successful application of AI and machine learning in our field requires thorough understanding, data quality, and ongoing research, as these systems are not perfect and require continuous monitoring and human expertise. In addition to the loudly-stated concern that AI will take human jobs, another challenge with machine learning systems is that they can act as “black boxes.” It’s often difficult or impossible to interpret how and why a machine learning model got its results, primarily due to their complexity and the large numbers of parameters involved.
We’re of the firm belief that when applied thoughtfully and in combination with human decision-making, AI and machine learning can help us build smarter, safer, and more sustainable transportation systems. It’s all about how we apply it—which brings us to our framework.

The successful application of AI and machine learning in our field requires thorough understanding, data quality, and ongoing research.
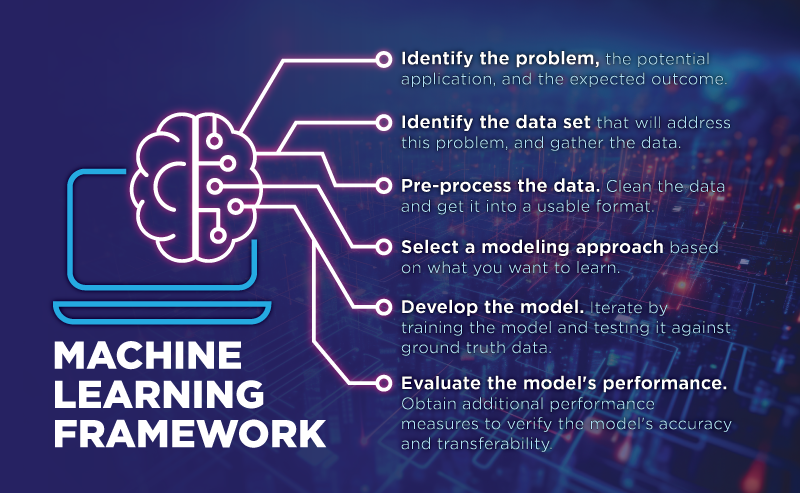
Our Machine Learning Framework: Six Steps for Pairing Machine Learning with Human Judgment
With these opportunities and challenges in mind, how can we develop machine learning models that take us to new places in our work—while we stay in control? Here are the six steps we follow to build a machine learning model that can be understood, verified, and ultimately relied upon (in the sense that we’re confident in what it can do, and also know what it can’t).
1. Identify the problem you need to solve.
What question are you trying to answer, and what are you expecting from the model?
2. Identify and gather the data that will address that problem.
Gather the data set(s) you need to address the problem. How much data you need depends on the application. Having more observations in a dataset can lead to a larger number of parameters and relationships between those parameters, which can make the data more complex. Machine learning can be a better candidate for handling complex data, as it excels at identifying patterns and relationships within large datasets. However, it’s important to note that having more data doesn’t always guarantee better results.
The quality of data is as crucial as the quantity. Ensuring that the data is accurate, relevant, and free from errors and anomalies is paramount. High quality data can lead to more reliable and meaningful insights, while poor quality data can introduce bias and inaccuracies into machine learning models. Data quality is a sum of many factors, including completeness, consistency, reliability, and how well it representatively reflects the problem being addressed.
3. Pre-process the data.
Clean the data and get it into a usable format for the machine learning model at hand. This step involves several important tasks:
- Data cleaning: Identifying and rectifying errors, missing values, and inconsistencies in the dataset to ensure data integrity.
- Feature engineering: Creating, transforming, or selecting relevant features to improve model performance and interpretability.
- Data normalization: Scaling the data to a common range or distribution to facilitate model convergence and effectiveness.
Because each model requires data to be in a specific format, step 3 goes hand in hand with step 4.
4. Select a machine learning modeling approach based on what you are looking to understand.
There are different types of models that can be built—for example, classifications, regressions, and clustering—depending on what you are looking to learn. Before we can build a model, we need to identify the approach we want to take with the data. Previous research should be taken into account—what has been done before and how can we pick up from where someone else left off? This step also involves selecting an appropriate evaluation metric based on the specific problem (accuracy, precision, recall, etc.).
5. Develop the model.
Step 5 typically a long step involving a lot of iteration. Now that the data is prepared for the approach and model we chose, we divide it into a training set (used to train the model, which learns from patterns in the data); a testing set (used to evaluate the model’s performance by assessing how well the model generalizes to new, previously unseen data); and in some cases, a validation set (used to fine tune the hyperparameters and further assess the model’s performance). Then we start developing and testing the model.
Every time we modify the architecture of the model, we train the model on a training dataset and test it on a separate dataset that has already been processed and verified, and see if the model produces results that match the “ground truth data.” A part of optimizing the machine learning model is tuning the hyperparameters. This process involves finding a set of optimal hyperparameter values for a learning algorithm while applying this optimized algorithm to any data set. We also check for bias-variance trade-off (the balance between a model’s complexity and the accuracy of its predictions).
We do this until we reach the best accuracy or expected outcome. For example, if crash prediction has been done at 96% accuracy through other research methods, our goal is to get even better results—but at minimum, we want to match that accuracy so that we know the model is keeping pace with what’s been done before.
6. Evaluate the performance.
In this step, we obtain additional performance measures to make sure the model works well and isn’t being influenced by outliers, over-fitting, or missing information. One way we do this is applying the model to a different data set (for example, in another location or at another time) to check its validity and transferability.
Putting the Framework into Practice
What do all of these steps look like, practically? Here are a few examples.
We created a Random Forest Regression machine learning model to help a statewide department of transportation understand discrepancies they were seeing in truck count data. Random Forest Regression predicts relationships among variables by creating decision trees and combining their estimations to make a final prediction. We obtained data from the DOT’s traffic monitoring sites and roadway segment characteristics, and trained and tested a model until we reached the point where comparison to ground truth data proved the model’s ability to closely approximate the actual truck volumes. The model was applied to estimate truck volumes in 2021. These estimated results were then joined back to the roadway segment shapefile, enabling the creation of a map to visualize the spatial distribution of estimated truck AADT ranges statewide.
The model must be refreshed annually given that each year presents unique conditions—which reinforces the need for human intervention and oversight—but offers several advantages over the prior methodology, including the ability to fill data gaps, a dynamic approach to roadway characteristics, and a streamlined process requiring less manual work.
Zooming in from the statewide level to the line at a fuel station, we’ve also been exploring how machine learning can help us address location-specific questions posed by both public agencies and businesses. For example, we’re building a model that takes in a variety of inputs—the inbound flow of trips generated, number of fuel pumps, time at the pump, land use patterns, seasonality, and time of day—and how each of these inputs contributes to the length of a vehicle queue. Compared to traditional ways of looking at queues, in which the best thing we could do was take averages, our machine learning algorithm provides a dynamic display of data that demonstrates which inputs are most influential on the length of the queue at any given time. One takeaway so far is that while small data sets can tell us when peak queues occur, we need more data on peak queue occurrences to answer how big those queues are (which, in turn, gives us enough information to understand what kinds of design and operational strategies we can use to manage the queue).
Internally, it has been fascinating for us to experiment with using artificial intelligence to automate processes and use resources efficiently. One example is our internal resume builder. Our team has built a tool that saves time in the creation and review of resumes for proposals by identifying team members and projects that align with new pursuits.
Continue the Conversation
These are just a few of many examples of how machine learning and AI can bring efficiency, accuracy, and innovation to projects when applied methodically and thoughtfully. There’s so much more to talk about! We invite you to reach out to any one of us to learn more about the framework we presented here, and how we can pair AI with human decision-making to build smarter and safer transportation systems.